I gave a talk to the Princeton chapter of the ACM on Model Minded Development.
Many slides have no text, so you’ll want to go to the Full slide deck with speaker notes.
The common denominator here is that software developers are expected to keep in mind many abstract yet complex models that constrain the code they write. In some ways these constraints are a burden and in other ways they are light that illuminates a path forward.
I discussed an idea called Model Minded Development that generalizes across DDD, Design Patterns, architecture, TDD, and coding styles. The defining characteristic of senior software developers is their facility with Model Minded Development and it enables them to operate at an advanced level.
Michael Keeling and I had a video Hangout on Air today, chatting about the intersection of software architecture and agile.
Some of the topics discussed include: 3-tier architecture, YAGNI, quality attributes, big design up front, little design up front, design patterns, architecture patterns, walking skeletons, thin vertical slices, spiral model, system metaphor, extreme programming (XP), application frameworks, MVC, publish-subscribe, refactoring, architectural refactoring, refactoring vs rework, refactoring-to-patterns, lean thinking, last responsible moment, keeping options open as long as possible, Michael Waterman (NZ), cost-value-curve, “I’d love to have that problem”, architecture mismatch, conscious design decisions.
This lecture, recorded at the University of Colorado Boulder in September 2012, is an introduction to the major concepts of software architecture. The audience consisted of 70 seniors majoring in computer science. It is based on material taken from the book Just Enough Software Architecture.
Most developers have no formal eduction in software architecture, yet a system’s architecture has a big influence on its success. Software architecture has been intensively researched for more than twenty years now and studying it will help you do a better job of designing systems, give you names for the concepts and patterns, and help you choose between competing designs.
Upgrading Drupal is always a bit stressful. It’s easy to get a site up and running and then customize it – but it’s exactly those customizations that can get lost in the upgrade. It appears to be all back to normal but let me know if you find anything that seems broken.
Earlier this year, I gave talks at the GOTO Copenhagen and GOTO Amsterdam conferences. A few folks at the conferences called it “the dandelion talk” because there is an example in the middle of my conceptual model of how to get rid of dandelions in your yard. Of course the real idea is that conceptual models of architecture can help you become a better software engineer – the difference between the 20-year-old version of yourself and the older, master-builder version of yourself. This is perhaps my favorite of all the talks I’ve given, so I hope that you enjoy it too.

GOTO Copenhagen talk on
conceptual models of software architecture
(Opens on InfoQ website; no easily embeddable video – but going to their site gives you both the video and the slides)
I presented my work on Architecture Hoisting last week in Atlanta. The big idea is that software often relies on global design constraints (guiderails) to achieve its qualities (e.g., reliability, security).
But you’ve really only got two options for ensuring those guiderails: (1) developer vigilance and (2) architecture hoisting. In the small (say inside of a data structure), using vigilance to keep an invariant is possible. In the large, architectural guiderails (self-imposed constraints that simplify the software) are much harder to ensure, as the recent remote exploit in Google Chrome (a use-after-free bug) illustrates.
The other option, architecture hoisting, has not been widely recognized so this talk gives it a clear definition, shows examples of it in use, and discusses its applicability and trade-offs.
Software architecture focuses on quality attribute requirements, such as scalability or performance, that are overall properties of a system. This talk describes Architecture Hoisting, a a design technique where the architecture ensures an intensional design constraint (i.e., a guiderail) to achieve a global property. Discussed examples include the NASA JPL Mission Data System, Enterprise Java Beans, and the Apache Portable Runtime.
I will be in Atlanta giving a talk on Architecture Hoisting next week at the local IASA chapter. The topic of architecture hoisting is in my book but I’ve had several requests to dig into it further and this talk is the result. Here’s the talk abstract:
Architecture hoisting is an established technique that has only recently been identified and named. It is suitable when you have a challenging design problem that requires consistency in the implementation. Architecture hoisting assigns responsibility for a problem to the architecture itself with the intent of guaranteeing a goal or property of the system. Once a goal or property has been hoisted into the architecture, developers should not need to write any additional code to achieve it.
A little while ago, several cases of my books were being shipped to Amazon by the US postal service but those cases went missing. The USPS claims to have never found them despite being well labeled and indeed having an Amazon packing list inside the box.
Fast forward to now and those books are showing up on Amazon and eBay. But all is not well! It seems they were sold by the USPS to scavengers who have put them up for sale. I’d thought that this would be no problem, but it appears that Amazon does not like it when others sell books below their wholesale price, so they’re penalizing my book and selling it at list price – but nobody pays retail prices for books.
So, rather than let the scoundrels profit, I’m letting readers profit. I’m selling the book myself as an Amazon Seller for $19.50 until the scavenged inventory makes its way through the system. So grab yourself an extra one and tell your friends since I’m not sure how long this will last.
–George
Franco Martinig has another blog post about my book, this time on Muddy architecture.
Franco Martinig of Methods and Tools has reviewed my book. Review of Just Enough Software Architecture.
This talk that I delivered at AgileRoots 2010 was recently posted (or at least I recently learned it was posted). It’s one of my favorite talks to deliver and the topic is important for all developers since writing code that expresses your design intent is hard but so very helpful for everyone who must read it later (including you!).
Because of Eric Evans’ Domain Driven Design, agile developers are familiar with embedding their domain models in their code, but architecture and design remain hard to see from the code. How can we improve that? This session presents a new agile technical practice, an architecturally-evident coding style, that lets you drop hints to code readers so that they can correctly infer the design and architecture. It builds upon ideas like Kent Beck’s Intention Revealing Method Name pattern and provides a set of lightweight coding patterns and idioms that let you express your design intent in the code.
Last week was an exciting one as the CompArch/WICSA conference came to my hometown of Boulder. I was one of the conference chairs, the one in charge of the unglamorous task of organization, but the good news is that everyone was delighted by that! We had a great mix of folks from two different backgrounds and there was lots of mingling and ideas shared between them. The reception dinner at the Red Lion Inn on the Boulder Creek (swollen with snow melt runoff) was really great. (And yes, that restaurant choice was Judy Stafford’s idea!)
I presented a tutorial on the idea of an “Architecture Haiku”, which is a super-short architectural description suitable for use in Agile projects. Architecture Haiku tutorial slides PDF. Here’s the description:
You can’t say anything in one page — or can you? An Architecture Haiku is a one-page, quick-to-build, über-terse design description. No project wants “shelfware” documentation, but many must communicate their design to others. Brevity is hard — what would you say in one page? With no page limit, experts suggest documenting everything but the kitchen sink. The one-page limit forces you to convey the essence of your design using compact language and concepts.
Normally, when someone starts talking about architecture, they can go on forever — it seems like almost anything can be considered architectural. Constraining the description to one page (an architecture haiku) forces people to make choices. Consequently, they have to be direct and use the most compact language possible. Another interesting thing is that it clearly isn’t BDUF (Big Design Up Front).
Most folks who are asked to write their architecture on one page have a hard time. The point of the tutorial is to demonstrate that it is hard — hence asking the participants to do it themselves — but also go give a whirlwind tour of the essential ingredients of an architecture description. E.g., modules vs. components, viewtypes (module, runtime, allocation), quality attributes, tradeoffs, drivers, architecture patterns (map-reduce, client-server, n-tier, …). These are elements that aren’t directly expressible in programming languages (i.e., bigger than classes), so most developers won’t have a crisp idea about them.
This tutorial’s direct objectives are to teach the participants how to tersely describe their architecture. This is desirable because few developers want to spend much time on architecture descriptions and one-page descriptions cannot take too long. The indirect objectives are to teach the canonical basics of software architecture including its terminology and standard abstractions. This normally dry subject is made interesting and relevant through the artificial one-page limit. Just as design patterns enabled compact, efficient communication about object- and class-level designs, software architecture concepts and terminology enables efficient communication about larger design ideas.
I also moderated a panel discussion on Agile and Architecture featuring Philippe Kruchten, Dean Leffingwell, Ryan Martens, and Michael Stal. In a straw poll of the audience, only a couple of people said they were skeptical that Agile and Architecture could work together – the vast majority thought there would be friction but that they could coexist on projects.
As of right now, the book has seven 5-star reviews on Amazon.com. The demand for the book has been so strong that I’ve had to order a second printing! That should arrive within a month. I’m also going to be distributing the book to international bookstores including Amazon in the UK and Germany. There have been quite a few e-book sales there, so now they can get the hardback too.
I just noticed that the book has nudged its way into the top-10 list for its category on Amazon (system analysis and design books). That makes me feel really good and I hope this helps it get better visibility.
There’s a new review of my book up on Amazon today. Here are some choice words:
Just Enough Software Architecture: A Risk-Driven Approach is the book I will now be recommending to software developers who either have no architecture-level experience, or who need to get back to the basics of what software architecture is really all about.
…for a cohesive treatment of software architecture, the goal of which is to start students and professionals on the right track, there are no other texts than can stand up to this one…
Thank you to all of you who have provided such kind words about the book. Yes, people really do read those reviews to decide what book to get!
I was interviewed in InfoQ by Srini Penchikala. My hope was to lay out the major themes of the book and build bridges to the Agile programming community. I’ve gotten a few supportive messages so I think people liked the interview overall.
Earlier, at the OOPSLA/SPLASH 2010 conference, I was interviewed by Kenji Hiranabe, whose company makes the best-selling UML tool in Japan. Here is part 1 and part 2 of the video interview.
My book is for sale on Amazon but its price has fluctuated wildly. This has happened enough times now that I’m willing to venture a guess. It seems that when the book is out of stock, the price drops to just under $44. When it is in stock, it sells for list price, $69.75.
I recently wrote to them to ask why my book was selling for list price while other architecture books were consistently discounted (e.g., the SEI books and Jim Copelien’s new Lean Architecture book). Their boilerplate reply was “We control the horizontal, we control the vertical, do not adjust your set” (Yes, a reference to The Outer Limits TV show).
If you’d prefer to pay a reasonable price instead of the list price (in truth, the list price is nominal and only used to set the mandatory 55% discount that Amazon gets), you have two options:
Buy the book from Softpro for $39.50. Softpro is a small, technical bookstore in Denver, so it’s doubly nice to be supporting the little guy.
Buy the book from me (Rhino Research) on Amazon for $39.75. The book is “Fulfilled By Amazon”, which means that it sits in Amazon’s warehouse, is shipped and packed by Amazon, is eligible for free super saver shipping, and has Amazon’s same return policy (not that you would return it). In other words, there’s really no difference.
Amazon.ca and Amazon.jp sell the book, but not (yet) Amazon.uk or Amazon.de. They (and any other bookstore in the world) could stock the book, they just haven’t, so if you want it, ask them to order it for you.
Of course there’s also the E-Book (PDF, ePub, Mobi) for $25. That seems to be the most popular option for those not in the USA.
First, apologies for the slow blogging recently. Things have been very busy and I’ve got a pile of topics I want to cover very soon. OOPSLA/SPLASH was great and there is plenty to talk about from that, plus I’ve picked up a few new tricks to explain architecture from a consulting project.
But today the news is my article on the Risk-Driven Model just published in CrossTalk magazine. The issue starts with a Q&A session with Grady Booch – quite nice to have an informal piece to find out what someone is really thinking – then my article, then an article on architecture and agility from the SEI (Nanette Brown, Rod Nord, and Ipek Ozkaya).
The article is derived from Chapter 2 of my book. I’ve attached the article (5.6MB) in case it disappears from their website.
Recently, I’ve been posting answers about architecture questions I’ve seen pop up in a few places. I’ll collect them here so that you can find them.
Agilists disagree about planning and architecture. XP tends to advocate no (or little) architecture up-front (i.e., planned design), but people like Martin Fowler say they do planned design maybe 20% of the time. Chapter 14 of XP Explained (Kent Beck) has a nice articulation of the XP design philosophy.
Michael Keeling has a good explanation about why agilists (and others) disagree. He says to pay attention to two dimensions: your knowledge about solutions and your knowledge about problems. When you know lots about solutions in this field (e.g., web systems), then you are more likely to defer planning. But when nobody has ever built a Mars Rover before, you do more planning. To me, this explains why engineers in different situations do different things, yet what each does is rational.
It sure took a long time, but the hardback book of Just Enough Software Architecture: A Risk-Driven Approach is now available on Amazon for $39.75. Makes an excellent present, or buy 4 at a time to hold your newspaper down flat. Great as a flyswatter. Kids and mothers love them!
And if you prefer, the PDF and e-book version is also available for $25. It takes up less space in your carry on luggage. As they say, “you can’t grep a dead tree”.
But the cheapest price on the hardback is to get it from Softpro books in Denver. Just $39.50 and you’re supporting a local bookstore.
I just got word from the printer that the hardbacks are due to arrive around August 31. That means they’ll be for sale at Amazon maybe a week later.
The printing job is kind of a leap of faith. I did get a proof of the insides and a proof of the cover, separately, but no complete book. And the process for creating the proof is different than for creating the real book, which is printed on an offset press. And what if the cover alignment isn’t right – will the spine text be off-center? Let’s just hope it looks good.
I’ll be delivering the Architecture Haiku presentation, possibly in an expanded form, at the Boulder Java User Group on 7 Sept 2010. The slides for the talk have been posted (thanks to DOSUG and Matthew McCullogh). They are also available as PDF.
Feedback on this talk has been pretty positive. I think this is because people would like to know how to do something helpful with a small amount of time – telling them how to create comprehensive architecture documents isn’t relevant because they don’t have that much time (and/or their projects are not risky enough to justify spending that much time). But writing down nothing is usually a problem too.
This talk suggests writing down about 1 page worth of information on a system, emphasizing ideas that get at the gist of the architecture and why it was chosen.
As promised last week, the e-book is now for sale. For $25, you get three DRM-free versions of the book: PDF, ePub, and Mobi. The ePub format works on pretty much every e-book reader — except the Kindle, which reads the Mobi format. Apple iPad owners will be happy to hear that the PDF page size is almost identical to the hardback page size, so the PDF looks great on an iPad. (Kindle owners say the same thing).
Also as promised, the price is pretty darn low for an e-book on software architecture. It beats the pants off of the price of similar books, which sell for twice the price or more.
So go buy the e-book now! And tell your friends!
While the “real book” is at the printer, I’ve been working on getting the electronic version of my book ready. If you have an e-book reader, please download the book preview as an ePub or as a PDF. Please let me know if you discover any problems and I’ll fix them before the e-book goes on sale.
With the hardback book, I’m trying to keep the price down. It’s hard to tell what Amazon will set as a price, but I’m hoping for around $40 for the hardback book. That’s cheaper than any similar architecture book. (You can safely ignore the list price they have up today — their wholesale price is 55% off list).
The e-book will be cheaper still: just $25. That price will include three e-book formats: ePub, Mobi, and the ubiquitous PDF. That is amazing two ways. First, no one else (that I’m aware of) gives you three formats for the price of one. And second, it beats the pants off of the price of similar books.
WICSA 2011, the 9th Working IEEE/IFIP Conference on Software Architecture, will be held in Boulder, Colorado next year, 20-24 June 2011. I have been asked to be on the program committee.
The program committee has released a preliminary call for papers. The paper submission deadline is 7 February 2011, so get your word processor fired up.
The text from the attached PDF follows after the break.
Just a reminder that I’ll be speaking about Architecture Haikus at the Northern Colorado Architect’s Group in Fort Collins, Weds 21 July 2010. I don’t yet have details on the venue or time, but I’ll edit this post when I get them.
An Architecture Haiku is a one-page, quick-to-build, uber-terse design description. No project wants “shelfware” documentation, but many must communicate their designs. 20 years of architecture research suggests that tradeoffs, quality attribute priorities, architecture styles, and constraints are short yet valuable.
Edit 9 Aug 2010: Slides from Architecture Haiku talk
I will be speaking about Architecture Haiku, a one-page architecture description, at the Denver Open Source User Group on Tuesday, 3 August 2010.
An Architecture Haiku is a one-page, quick-to-build, uber-terse design description. No project wants “shelfware” documentation, but many must communicate their designs. 20 years of architecture research suggests that tradeoffs, quality attribute priorities, architecture styles, and constraints are short yet valuable.
Edit 9 Aug 2010: Slides from Architecture Haiku talk
My apologies if small updates like this are boring, but the book copyedits came in today and they’re all trivial. This is good. They’re things like missing periods, a few misspelled words, missing/extra hyphens (ie usage differences), and so on. I should be able to incorporate these into the manuscript today and have it back to the publisher.
I don’t expect that this will hasten publication because they have to schedule time with the printer. But I’d be happy to be wrong!
And I’ve just noticed the book price is down to $40.46 on Amazon. I wonder what their low price guarantee means for pre-orders. In particular, will Nels (the first order) get the new, lower price?
Edit 11 July 2010: Price is now $39.75, set by me. Note the new Amazon page for Just Enough Software Architecture.
Let me be clear about something you probably already know — writing computer books is a terrible idea for a way to get rich. For each book that the publisher sells, I get a small percentage of the profit. Yes, profit, not the gross, so I’ll be surprised by how the accounting works. A friend of mine who is a prominent author at the SEI told me that he’s happy to get a nice dinner out of his royalty check each year!
That said, I’m very happy that my publisher has agreed to drop the retail price of my book by $10. What that means is that Amazon is offering my book right now for $47.21 with free shipping. That’s not cheap, but it’s not the $65 for the Taylor book. (Gee, that was $90 just a month ago. Its price is bouncing around.)
The other bit of news is that we’re starting up a software architecture and design group in Boulder. You can sign up and come to our meetings. The first meeting is in about a half our at Sherpa’s restaurant (yum!).
Edit 11 July 2010: Revised Amazon link
I just got back from AgileRoots 2010 in Salt Lake City (more on that soon) and have gotten two bits of good news about my book. First, Lisa Haney has finished the cover illustration! She is also doing the rest of the cover design and that’s not done yet, but I’m really excited just to see the illustration. I went ahead and put some placeholder text on it so that you can get an idea of what it will look like. Here’s the larger version.
The other bit of interesting book news is that there is now an Amazon page for Just Enough Software Architecture. I still have to put up a page for me as an author, but this is a good first step. BTW, the latest news is that the book will be out in October, but I see that Amazon thinks it will be out Sept 21.
Edit 11 July 2010: Revised Amazon link
Well, look what I’ve done. Judy Stafford is one of the co-General Chairs for the WICSA/CompArch 2011 conference and has asked me to be the Local Arrangements Chair. That means that if you have preferences, you should let me know and will see what I can do. Want an event at Chautauqua? Hiking? Let me know.
I was posting the kind words that reviewers had for my book, but then I got overloaded as they came in very quickly and I was working to get the book final draft out to the publisher. So my apologies to those that didn’t get their own blog post. I have posted the complete list of review quotes, and will be updating it as more come in.
Offline, I have gotten a few additional comments that make me really happy:
Page 79 is awesome. Pure gold.
With luck, other pages are at least bronze. And another:
I really like the book., it reminds me of many things we learned in the MSE program. And it also gave me an idea how I could apply that in a “real world” project. This is definitely a book which I will recommend to my friends!
I’ve been working on the book WAY too long to have anything like an objective opinion on it, so it feels really good to hear that it’s helpful for others.
Philippe Kruchten’s keynote talk from the SATURN conference has been posted at the SEI. His slides are worth taking a look at: moderate in the agile architecture debate but full of real ideas, not just best hopes of compromise.
Thanks to my friend Alan Birchenough explaining the RUP to me, I was able to see how this presentation hinted at Kruchten’s ideas about risk and architecture (p 17 of the slides). In the RUP, a software project has four phases — not because you impose them, but because they almost always end up that way. The first phase is inception, where you are just trying to understand what the project is about. The second phase is elaboration, where you are deciding how to build it. The third phase is construction, where each iteration focuses on delivering new features. The fourth phase is transition, where the software is introduced into the end-users.
Kruchten points out that risks must be addressed early, in the inception and elaboration phases. When you hear architects worried about agile practices, you can usually decode what they are saying into “a pure feature-focus lets risks linger”. It may sound like this, “If you don’t design for security (or scalability, etc.) then when a user story asks for it, in the 20th iteration, you may find it difficult or impossible to add”. Kruchten quotes Tom Glib, saying “If you do not actively attack the risks in your project, they will actively attack you”.
It’s easy to see how this kind of risk aversion can slide into Big Design Up Front. I was on a project where one of the designers decided that logging was a risk, so he’d best design the logging framework first. The way off of this slippery slope is to brainstorm then prioritize all your risks (this can be just a 10 minute activity). Some risks will “make the cut” while others will not. And it’s no substitute for good judgment, only a technique that informs your good judgment — so if you believe logging really will sink your project, brainstorming and prioritizing risks won’t change your mind.
The slides include his 4-color backlog idea, where user-visible features, bugs, technical debt, and hidden architectural features are all on the backlog. I like this idea a lot because it helps reveal dependencies, as in “we cannot build that user story until this architectural feature is in place (or this technical debt is removed)”.
Many organizations struggle to choose the most appropriate courses to advance their people. They struggle because, while it is relatively easy to describe their desired end state, the path to get to it is unclear.
Software architecture education is particularly tricky. If you take a class on Java or Struts, you do so because you do not yet know that language or framework. But everyone has some ability to design programs already, so it is not clear what benefit will come from a general class on architecture and design. If you are considering an architecture class, you suspect that your team would benefit from software architecture and design education, but are having a hard time putting your finger on exactly what is missing. As a consequence, it’s hard to be sure if any particular course is what the team needs.
I’ve just had a rather enjoyable “refactoring session” with my book. At first, I had some good content sections lumped together into a catchall chapter — Working with Models. But, as the book fills out, it becomes easier to see where those sections should fit, so I was able to refactor the outline to introduce a new chapter on Encapsulation and Partitioning that will hold several of those sections.
When a coach and a rookie watch the same game, they both see the same things happening on the field, but despite the rookie’s eyes being younger and sharper, the coach is better at understanding and evaluating the action. As a software developer, you would like to understand and evaluate software as effectively as the coach understands the game. This chapter will help you build up a mental representation of how software architecture works so that when you see software you will understand it better and will design it better.
If you want to become as effective as a coach, you could simply work on software and wait until you are old. Eventually, all software developers learn something about architecture even if they sneak up on it indirectly. It just takes practice, practice, practice at building systems. Consider another path, one where you see farther by standing on the shoulders of others. Perhaps we are still waiting for the Isaac Newton of software engineering, but there is plenty to learn from those who have built software before us. Not only have they given us tangible things like compilers and databases, they have given us a set of abstractions for thinking about programs. Some of these abstractions have been built into our programming languages — functions, classes, modules, etc. Others likely will be, such as components, ports, and connectors.
For technophiles like me, it was amazing. A friend was playing music at his party via iTunes – nothing unusual there – but he was controlling it from his sofa using his phone. Lots of folks play music at parties from their laptop, but he had an application that showed him the songs in his library and let him queue up songs to play. Since I had a smartphone too, and technical pride was on the line, I decided to find or build a similar application.
On the internet, I found an app for my phone. It was visually attractive and had many features even though it was an early release. However, when I ran it, I found some problems. Initially, I the app would not talk to my media center and it was hard for me to diagnose why. And navigating through the pages of the app was slow – even backing up a page caused a noticeable lag.
After looking at the code, I realized that these problems could be fixed by rewriting the communication library it was using. To solve the problems, the library needed to cache results and report more details about connection errors. In a minor way, the application had an unsuitable architecture.
I upgraded this Drupal-backed website theme from Garland to Zen CTI-Flex. Please let me know if you find anything broken and I’ll do my best to fix it. The CSS in the Zen theme is, to me anyway, more comprehensible and maintainable.
As they build successful software, software developers are choosing from alternate designs, discarding those that are doomed to fail, and preferring options with low risk of failure. When the risks are low it is easy to plow ahead without much thought, but, invariably, challenging design problems emerge and developers must grapple with high-risk designs, ones they are not sure will work.
To address failure risks, the earliest software developers invented design techniques that helped them build successful software, such as domain modeling, security analyses, and encapsulation. Today, developers can choose from a huge number of design techniques. From this abundance, a hard question arises: Which design and architecture techniques should developers use?
If there were no deadlines then the answer would be easy: use all the techniques. But that is impractical because a hallmark of engineering is the efficient use of resources, including time. One of the risks developers face is that they waste too much time designing. So a related question arises: How much design and architecture should developers do?
Decade after decade, software systems have seen orders-of-magnitude increases in their size and complexity. This is remarkable — and more than a little scary for those of us who build software. In contrast, imagine how hard basketball would be if it scaled up the same way, with 5 people on the floor one decade, then 50, then 500. Because of this growth, today’s software systems are arguably the largest and most complex things ever built.
Software developers are always battling the ever-stronger foes of complexity and scale, but even though their opponent grows in strength, developers have staved off defeat and even reveled in victory. How have they done this?
One answer is that the increases in software size and complexity have been matched by advances in software engineering. Assembly language programming gave way to higher-level languages and structured programming. Procedures have, in many domains, given way to objects. And software reuse, which used to mean just subroutines, is now also done with extensive libraries and frameworks.
Today I sent the electronic book sources to the publisher. What follows is several rounds of copyediting to make sure that you, gentle readers, don’t have to suffer through typos, etc. Sadly, it will take 5-6 months in the production process, so it will arrive on bookshelves (whatever those are) and on Amazon in November or December 2010.
Thank you to everyone who has helped me along the way with supportive comments, reviews, and all kinds of other help!
I’m honored to have received the following endorsement from Michael Keeling, a blogger on software engineering. I met Michael at the last OOPSLA conference while attending the workshop on Agile and Software Architecture. He is a graduate of CMU’s Master of Software Engineering program.
Just Enough Software Architecture says what everyone is thinking but can’t say because they are tied to various methodologies: Big Design Up Front is bad, you don’t have to document everything, and everyone from the lowest programmer to the project manager needs to understand not just what the architecture of the system is but also why that architecture was chosen. The risk-driven approach to design presented in this book helps software developers understand how much design is needed so they can quickly get back to writing code and providing value to customers in the form of working software.
If you’re only going to read one book on software architecture, start with this one. Just Enough Software Architecture covers the essential concepts of software architecture everyone – programmers, developers, testers, architects, and managers – needs to know; and it provides pragmatic advice that can be put into practice within hours of reading.
—Michael Keeling, Software Engineer at Net Health Systems Inc.
I’m honored to have received the following endorsement from a client who works at at NASA’s Johnson Space Center.
The Risk-Driven Model approach described in George Fairbanks’ Just Enough Software Architecture has been applied to the eXtensible Information Modeler (XIM) project here at the NASA Johnson Space Center (JSC) with much success.
George’s approach illustrated to the customer why the system was designed the way it was from its service layer, data-access layer, dependency injection support, and even its data architecture. The high-high quality attribute pairs that fell out of the architecture process justified the tasks, schedule, and cost of the project. The modeling constructs have helped communicate the architecture among all team members and even to prospective new customers. The architecture has allowed the XIM project to be a success here at JSC and it can help your project be a success as well.
It is a must for all members of the project from project management to individual developers. In fact, it is a must for every developer’s tool belt. (The Code Model section and the anti-patterns alone are worth the cost of the book!). Using “Just Enough Software Architecture” and involving the whole project team in the approach will go a long way towards project success.
—Christopher Dean, Chief Architect, XIM, Engineering Science Contract Group – NASA Johnson Space Center
I’m honored to have received the following endorsement from a friend who works at Microsoft. I previously worked with Nicholas at Carnegie Mellon in David Garlan’s software architecture research group.
Just Enough Software Architecture will coach you in the strategic and tactical application of the tools and strategies of software architecture to your software projects. The first contribution of this book is a insightful guide that will help you identify the driving characteristics of your project and develop goals, value propositions, and implementation strategies for the role of architectural modeling in your project. Dr. Fairbanks goes on to provide clear instruction in the tactics and the tools of architectural modeling that will enable you to achieve your goals for the overall project. Whether you are a developer or an architect, this book is a solid foundation and reference for your architectural endeavors.
— Nicholas Sherman, Program Manager, Microsoft
I’m honored to have received the following endorsement from a top software architecture expert from the Software Engineering Institute. Paulo has been reading drafts of my book, Just Enough Software Architecture, over the past few months and provided essential insights that have improved the book greatly.
This book reflects the author’s rare mix of deep knowledge of software architecture concepts and extensive industry experience as a developer. If you’re an architect, you will want the developers in your organization to read this book. If you’re a developer, do read it. The book is about architecture in real (not ideal) software projects. It describes a context that you recognize and then it shows you how to improve your design practice in that context.
— Paulo Merson, Visiting Scientist at the Software Engineering Institute, and practicing software architect
My friend from CMU (now at Microsoft), Jeff Stylos, mentioned in a presentation that the .Net framework was so big that its documentation was bigger than, well, I’ll let him tell you (excerpted from an email with permission):
So yes, to paraphrase Eddie Murphy, that stuff is big.
People used to say that nobody ever got fired for buying IBM. IBM mainframe systems dominated the market and the assumption was that choosing an IBM system was reasonable. Today, many domains have a software architecture that dominates the same way that IBM mainframes once did. These are presumptive architectures.
A presumptive architecture is a software architecture (or a family of architectures) that is dominant in a particular domain. Rather than justifying their choice to use it, developers in that domain may have to justify a choice that differs from the presumptive architecture. Incurious developers may not even seriously consider other architectures or have the misapprehension that all software should conform to the presumptive architecture.
InfoQ has posted an interview with Philippe Kruchten from SDC. In it, he talks about agile, architecture, and process among other topics. Here are some bits I found interesting with some commentary.
I’m speaking at the SATURN conference in Minneapolis next month. If you are thinking of going, now is the time to register so that you can get the $650 registration (instead of $950).
Once I am done with this book, I have good intentions of creating a Slashdot-like site devoted to software architecture. I’m frustrated with how hard it is to find interesting material and I hope others would be willing to help me feed the site. Until then, here are some interesting links I’ve come across:
Comments and suggested links are welcome.
Edit 30 May 2010: The new software architecture site is live.
An old friend called me up last week to have lunch and pick my brain on software architecture. We’ve worked together building software in the past but he’s been tempted by the dark side and is now the CEO of a startup company. He needed his engineers to build an architecture model of their running system ASAP. Fortunately, I had some materials ready for him to glance over.
After he and his engineering team read over my book, they drew up a model of their system and I reviewed it with them. First off, they fell victim to a few anti-patterns listed in the book (perhaps they skimmed over those sections):
We had a nice session looking at the diagram using a projector on the whiteboard, sketching edits on the projected image while one of the engineers made edits to the diagram in near-realtime. After a bit of question and answer between me and them, I learned that their boxes fell into three traditional IT categories: user interface, business logic, and persistence. We rejiggered the diagram so that these boxes fell into columns and then labeled the columns. Aha, it was clear this was a 3-tier system.
One of the boxes had to span tiers. They had offshored the development of that piece and its code jumbled the UI and business logic together. This became clear by the way we drew it, spanning two columns. We also discussed their future plans to rework that box and their rationale for outsourcing its development.
This led to the next part of our discussion: rationales and tradeoffs. They had described the “what” of their design, but not the “why”. Rationales and tradeoffs are simple and compact to write down but give great insight into why things were designed just so. For example, they had outsourced development in order to get to market faster and the code seems to be reliable enough, but over time it is a hindrance to modifiability.
There were two joys for me. The first was working with this fun and motivated team. Sometimes I walk in at the request of a manager and there is resentment from the team and they are surly and defensive. Not this time — we had a wonderfully productive session. They were genuinely happy about how quickly (I was there maybe 90 minutes) we cleaned up the diagram and made it express the essence of their engineering.
The second joy was in validating my book. If you’ve ever been part of a creative effort like writing a book, you know that your baby has warts but you hope that despite all its problems it is a net improvement to the world. It was great to have them skim my book, apply the ideas, and be in good shape with just a few nudges. I bet if they’d had time to read the book completely it would have been even faster. So chalk one up for practical software architecture advice.
I’ve been quiet on the blogging front but that is because I’m in the final push on the book, which should be going to the publisher in about a month. If any of you would like to review a chapter, please let me know and I’ll send it off to you. At this point I’m not looking for wordsmithing/typo feedback, but things like missing references to related work or arguments that need to be strengthened. There are already a couple chapters posted for you to get a taste of what the final book will be like.
Why am I the last one to learn these things? :-) This from the IFIP page:
WICSA 2011 will be held June 2011 in Boulder, CO co-located with CompArch.
Even if they’re not here because of me, I’m happy.

I will be speaking on 6 May 2010 at the Denver IASA IT Architecture (ITARC) Conference. And yes, I have the coveted 5:30-6:30pm slot :-) The talk will be about Architecture Haiku: One-Page Architecture Descriptions.
You can’t say anything in one page — or can you? An Architecture Haiku is a one-page, quick-to-build, uber-terse design description. No agile project wants “shelfware” documentation, but many must communicate their design to others. Brevity is hard — what would you say in one page?
20 years of architecture research suggests that tradeoffs, quality attribute priorities, architecture styles, and constraints are short yet valuable. This tutorial teaches a new agile design practice that helps your team understand its design and communicate it with others.
Normally, when someone starts talking about architecture, they can go on forever — it seems like almost anything can be considered architectural. One interesting thing about constraining the description to one page (an architecure haiku) is that it forces people to make choices. Consequently, they have to be direct and use the most compact language possible. Another interesting thing is that it clearly isn’t BDUF.
Most folks who are asked to write their architecture on one page have a hard time. The point of the tutorial is to demonstrate that it is hard — hence asking the participants to do it themselves — but also go give a whirlwind tour of the essential ingredients of an architecture description. E.g., modules vs. components, viewtypes (module, runtime, allocation), quality attributes, tradeoffs, drivers, architecture patterns (map-reduce, client-server, n-tier, …). These are elements that aren’t directly expressible in programming languages (i.e., bigger than classes), so most developers won’t have a crisp idea about them.
The conference is cheap — just $150 if you join IASA ($50) and register in early April.
Edit 9 Aug 2010: Slides from Architecture Haiku talk
In case you were wondering what my book on software architecture will be like, you can now see the video that describes its basics. This talk was given at a joint session of the Denver IASA and the Agile Denver groups on 16 November 2009. The topic is the Risk-Centric Model of software architecture, which helps you answer the question, “How much architecture/design should I do?”
The first 17 minutes of the talk are a quick summary of software architecture; the remainder describes the Risk-Centric Model.
Here is a direct link to the video, in case you cannot see it embedded here: An Introduction to Software Architecture and the Risk-Centric Model from George Fairbanks.
Here is a short excerpt from my forthcoming book on software architecture:
Over time, a team understands increasingly well how a system should be designed. This is true regardless of which kind of process a team follows (e.g., waterfall or iterative processes). In the beginning, they know and understand less. After some work (design, prototyping, iterations, etc.) they have better grounded opinions on suitable designs.
Once they recognize that their code does not represent the best design (e.g., by detecting code smells), they have two choices. One is to ignore the divergence, which yields technical debt. If allowed to accumulate, the system will become a Big Ball of Mud. The other is to refactor the code, which keeps it maintainable. This second option is well described by Brian Foote and William Opdyke in their patterns on software lifecycle.
Refactoring, by definition, means re-design and its scale can vary. Sometimes the refactorings involve just a handful of objects or some localized code. But other times it involves more sweeping architectural changes, called architecture refactoring. Since little published guidance exists, architectural refactoring is generally performed ad hoc.
Yes, embedding a Dilbert cartoon is just too easy – but it provides a memorable lesson about why quality attributes, by themselves, are not as good as quality attribute scenarios. Before I bore you, the cartoon:
Perhaps it is important for your system to have security. We could all guess what that means, but we’d all likely guess slightly different things. I might guess it means that bad guys could not retrieve info. You might guess it means bad guys could not alter info. And someone else might point out that there is no currently known way to allow good guys to retrieve and alter info without a dedicated bad guy having some chance of access.
I will be speaking about Design Fragments and software frameworks at the University of Colorado (Boulder) computer science colloquium on 4 March 2010 at 3:30pm.
I’ve posted a couple updated book chapters here. The biggest change is a reorganization of the book. The first part now deals with risk-centric architecture and does not delve into specific ways of modeling architecture, reserving that for the second part of the book.
The two revised chapters are:
If you are new to software architecture, these provide a good introduction to what it is and how you can do “just enough” architecture (rather than wasting lots of time or painting your project into a corner).
I will be presenting a lecture on Design Fragments at the Boulder Java User Group meeting on 9 February 2010 at 6pm (before the pizza break). The lecture will be based on my thesis work. You can find a preview slide presentation on the work here. More details, including the full thesis, are available here.
You can watch a video of this talk, given at CU Boulder.
The following picture shows a UML static structure diagram of a design fragment. It shows the framework classes involved with creating an Eclipse context menu (right-click menu) and the classes that a developer must implement. The complete DF would also include behavioral specifications. (Apologies for the cropped text in the SVG diagram).
Frameworks are a valuable way to share designs and implementations on a large scale. Client programmers, however, have difficulty using frameworks. They find it difficult to understand non-local client-framework interactions, design solutions when they do not own the architectural skeleton, gain confidence that they have engaged with the framework correctly, represent their successful engagement with the framework in a way that can be shared with others, ensure their design intent is expressed in their source code, and connect with external files.
A design fragment is a specification of how a client program can use framework resources to accomplish a goal. From the framework, it identifies the minimal set of classes, interfaces, and methods that should be employed. For the client program, it specifies the client-framework interactions that must be implemented. The structure of the client program is specified as roles, where the roles can be filled by an actual client s classes, fields, and methods. A design fragment exists separately from client programs, and can be bound to the client program via annotations in their source code. These annotations express design intent; specifically, that it is the intention of the client programs to interact with the framework as specified by the design fragment.
We can provide pragmatic help for programmers to use frameworks by providing a form of specification, called a design fragment, to describe how a client program can correctly employ a framework and by providing tools to assure conformance between the client program and the design fragments.
I built tools into the Eclipse IDE to demonstrate how design fragments could alleviate the difficulties experienced by client programmers. I performed two case studies on commercial Java frameworks, using demo client programs from the framework authors, and client programs I found on the internet. The first case study, on the Applet framework, yielded a complete catalog of twelve design fragments based on our analysis of fifty-six Applets. The second case study, on the larger Eclipse framework, yielded a partial catalog of fourteen design fragments based on our analysis of more than fifty client programs.
This work provides three primary contributions to software engineering:
InfoQ has a nice interview with Rebecca Wirfs-Brock on agile and architecture. From the interview, it is clear she is not a 100% emergent-design proponent, yet she has helpful advice on how design/architecture can fit into agile processes.
Here are some architecture-related quotes of interest:
I will be speaking about Risk-Centric Architecture at the joint IASA Denver / Agile Denver meeting on Monday Nov 16th, at 5pm. Location: PPA Event Center (2105 Decatur St Denver, CO 80211-5125).
http://www.iasahome.org/web/denver/home
Here are the slides on risk centric software architecture.
Kevin Bierhoff, Ciera Jaspan, Jonathan Aldrich, and I submitted a paper to ICSE that tries to describe what frameworks are today, since the academic literature on them is becoming a bit dated. The paper draft is here. The abstract is:
Software frameworks have changed significantly since they were described by researchers more than a decade ago. They have entered mainstream use in most domains of software development, and their structure and interaction mechanisms have evolved. This paper provides a revised definition of frameworks and surveys commonly used frameworks to extract two categorizations: a categorization of the different kinds of frameworks found in the wild and a summary of common interaction mechanisms employed by frameworks. Four popular frameworks are described in detail to illustrate these findings. The paper also discusses unique framework challenges and avenues for future research on frameworks.
I believe there is a difference between architecture and detailed design, but it’s hard to make a clean distinction. The problem is that some small details are architectural while others are not. Unfortunately, this has led some authors to say that architects get to decide what is architecture and what is not, which is unsatisfactory. I am in the process of developing my own definition which explains more. Here’s my best shot:
It’s been a while since I posted a blog entry because I’ve been head-down working on the book. Here’s a position paper for an OOPSLA workshop that I will be attending. The abstract is:
Developers are faced with a smorgasbord of architecture activities but few models telling them which activities to use. Alternatives include the documentation package model, which advocates a complete architectural description from many perspectives, and the evolutionary design model, which advocates no up-front architectural work. This paper introduces the risk-centric model, inspired by Attribute Driven Design (ADD) and the Spiral model. Risks are central, so developers: (1) prioritize the risks they face, (2) choose appropriate architecture techniques to mitigate those risks, and (3) re-evaluate remaining risks. It encourages “just enough” architecture by guiding developers to a prioritized subset of architecture activities. Like ADD, and unlike the Spiral model, the risk-centric model is not a full software development process and can instead be used inside a process such as XP or RUP.
Here is a draft of the paper: The Risk-Centric Model of Software Architecture
Revised 28 Sept 09: I’ve attached the final version of the longer paper and have put the short (1-page) version inline here.
In general I think the work done by the SEI is valuable and an asset to our field. My main concern is that the nature of projects they tend to be involved with is different than the ones I see. My guess is that they help out on the development of more tanks, electrical grids, and avionics systems than I do. I tend to see business systems (IT, banking) and web applications. The good news is that despite these differences I think we are describing different parts of the elephant rather than describing different animals.
When I started my book I had a boogeyman in mind: the chief architect.
I searched around and could not find information on how long a Quality Attribute Workshop (QAW) should take. My guess was between 1 and 3 days, depending on the project size, state of the design, and number of stakeholders.
The risk-centric approach I propose isn’t exactly what the Software Engineering Institute proposes. They tend to be more bureaucratic and methodical, which makes sense if you’re developing projects like the electric grid, a fighter jet, or even just software that controls the brakes in your car. The QAW, however, is one of their lighter-weight techniques, especially compared to things like the ATAM. My work assumes you know what the risks are, so the QAW is a nice compliment in that it describes how to solicit and prioritize quality attributes from a diverse group of stakeholders.
I asked Tony Lattanze, one of the authors of the QAW, for advice on its duration. Here’s his reply:
I’m having a great discussion with Larry Maccherone over on his blog. I’ve included my reply here, which will make more sense if you’ve read his original posting. Excerpts from his posting are in the block quotes below.
Hi Larry,
Thanks for chatting with me about this. It’s helping me to understand and articulate my ideas, and it’s stretching my thinking.
It struck me when you said this:
Agilest will argue that feedback from actual running code is the best way to battle complexity and scale. Tighten the feedback loop with actual code. You can make more rapid progress by building something, even the wrong thing, and re-building it, than you can by wasting time modeling it and thinking about it because the assumptions you make when thinking about it always miss something important. You’ll call that something an insignificant detail. They’ll say, it’s the details that end up getting you.
I’m a strong supporter of the spiral model and iterative development. Many folks who propose doing architecture do indeed suggest you do Big Design Up Front. I disagree (in most cases). When an agile developer sits at the keyboard, he’s thinking of what he’s building before he types. He’s not a monkey getting lucky typing Shakespeare. “Am I violating a design principle here? Is it OK for the front end to talk directly to the DB?” I know agile developers think about these things, and these are things I consider part of architecture.
One of the points I’m trying to hammer home in the book is that your architecture effort should match the risk. Small risks can be resolved at the keyboard in a coding session. Bigger risks may need prototyping or modeling. Really serious risks might require formalisms and analysis (e.g., avoiding priority inversion as happened on the Mars Rover).
I may have hinted at something that makes you think I’d disagree with “Tighten the feedback loop with actual code”, and I want to find where that is and not only eliminate it but actually reinforce that I agree with writing actual code. Here are some excerpts from Chapter 2: “We could keep adding models that explained more about our system, but spending effort building and maintaining models must be traded off against building the system” … “We must prototype our design to ensure it is viable before we commit more time and effort.” … “Prototyping can accelerate learning. Problems that seem easy at 10,000 feet often have unforeseen difficulties. Use research and prototyping to discover assumptions baked into COTS components, and express those assumptions in your models so you do not have to re-discover them later.” and then in the summary “A point that should be clear is that architecture modeling by itself is insufficient. Before modeling, we usually need to learn about our domain, which takes many forms. Prototyping is essential before proceeding too far with modeling, because continuing to work on a model with unvalidated assumptions is itself risky.”
Re-reading what I wrote (and I’m not sure if you’ve looked at Ch2 anyway), I’m concerned that people could see “prototyping” and think “throw-away”, but what I’m trying to convey is that Yes, there will be details and wrinkles that your models won’t see and you must write code to get feedback. Those are most certainly not insignificant details. I do not want tether this idea (write code!) to Agile specifically, but maybe it would be clearer to discuss that this need to reduce risk by writing code is one of the Agile core principles. Thoughts?
I think you will lose the argument if someone comes up with a story about how Google’s (substitute, amazon web services, apache, or some other well known “big” system) massively scalable (although arguably not complex) system was created iteratively without any serious architecture work. Then, your approach to architecture is no longer design; it’s archeology, a concise way to document a system after a real engineer built it. I suspect that Eclipse was built with a more structured approach. Do you know if they followed an architecture approach?
I’m pretty sure that engineers/developers on large systems have some way of thinking about the big chunks, and they analyze that thinking to ensure the design gets them where they want to go, then they write some code to be really sure. Of course, once they write code they learn it’s more complex than they thought or that their design had bugs in it, etc., and they iterate. The point I’m making is that they neither 1) randomly write code, nor 2) fail to have the big picture in mind before they write code. Of course you’re not suggesting that either, but I want to make sure we agree that there’s thinking about the design before coding. So let’s agree to call that big picture a model, even if they do not write it down, and call that thinking “analysis”.
Perhaps I need to make the point more clearly that I’m not advocating the following: Developers should think hard about problems, fire up a CASE tool and design a solution, then code it up. Iterate as necessary.
Closer to what I advocate is: When your system is big and complex you won’t be able to build it unless you can fit the problem and solution in your head. This means constructing models, which by definition elide details. These models might be in your head, on a whiteboard, or in a CASE tool. You will use these models to convince yourself that the code you are about to write (ie the design) will probably work (ie achieve functions and qualities). Serious risks might force you to write out detailed models that you analyze carefully, but small risks might entail whiteboard sketches and quick prototyping. NASA is probably going to build more models than MyStartup.com, but perhaps friendster.com would not have failed because of performance problems if they had done more design work.
(BTW, I have no inside knowledge of the Friendster case, but my reading of the post-mortems says that they wrote a system that didn’t scale with users, were convinced to rewrite it in a different programming language, which also did not scale, then changed programming languages again but also tweaked mySQL’s implementation to make their queries more efficient, which finally gave them acceptable performance but too late. The paper I read had the flavor of “my favorite programming language rocks” but it seemed clear that the DB tweaks were the solution, and the PL was not relevant to the scaling problem.)
Another way to lose the argument is by frameworks. I know architects whose job is mostly done once they decide what framework to use. Can you make the case that your approach could be used for them to make this decision? Be careful, most folks make the choice based upon things like how little boilerplate it makes you write, and the syntax of the templating language (Exhibit A). I see tons of discussion and thought go into the difference between SQLAlchemy and Hibernate’s approach to ORM versus RoR’s or Django’s. Can you address these things with your approach?
Frameworks are a great example of where almost every client program is a big ball of mud, with only a few exceptions — like Eclipse since it encourages building sub-frameworks using OSGi plugins/components.
I’ve just deleted a huge rathole I was starting about what appears to be desirable vs. what is actually what the project needs. We can go in to that later if you like. I bet we can agree that there are many cases where developers might prefer to use X because it’s fun, elegant, new, etc. but not the best choice for the project. Of course other times you’d be foolish to use unsharp or inefficient tools. I think it’s worth questioning if my liking to use language/tool X translates into project success.
Currently fwks and architecture models are oil and vinegar. If I did another dissertation it might be on this topic. It’s on my list of things that are still hard about architecture.
I’m not sure what the right answer is for you. I’ve never been much of a believer myself. I hate to say that without reading the other draft chapters. I’ll probably do that some time but I don’t have the time right now.
It’s not clear what you are expressing concern about: is it the idea of using architecture abstractions, or spending time drawing out models? One of the novel (I think) parts of the book is that you should do just enough modeling to discharge your risks, then start building. Other books tell you how to draw out all kinds of models about everything. This one says no, just model when you are worried, and stop modeling when you stop worrying. It could be that for most projects that Agile is applied to (small to medium IT projects are its bread and butter, or at least they used to be) that there are relatively few risks worth spending much time on. They copy the standard styles (usually N-tier or J2EE) and standard solutions (eg use DB to handle concurrency), so most of the time it works out.
I don’t want to throw your own words back at you but do you remember writing this? …
I’m almost ready to say and mean “software architecture should be taught immediately after data structures”. Of course we first have to figure out how to teach it. I can’t remember if this idea made it into the paper you’re quoting, but I thought of the math analogy — you used to have to mentor with a mathematician and even then by your 20’s you were only doing what we now consider elementary school math. We got better at teaching math so now we do long division in 3rd grade (though your average bar patron will struggle with it). You might not realize that the quote above was challenging an earlier paper by someone I highly respect, David Garlan, who had a few years earlier written a paper concluding that it was relatively easy to teach architecture. I will point out that he may be able to teach it better than I can, but I did have trouble.
Can you imagine how much more interesting an OS class could be after taking an architecture class?
Yes, getting general developers to read and embrace the book will be difficult. Perhaps the best entrance is as you suggest, with “architects”. (You probably haven’t read far enough to see my criticism of the term and explanation of why I don’t use the term in the book). I really think this kind of dialog with you is helping me to express myself more clearly, and to address concerns that Agile and other reasonable developers will have, so maybe there’s hope yet for the general developer audience).
Sorry to be so glum. I kept going because I was hoping to come up with a good angle for you. Instead, I just ended up with a long depressing discussion.
One thing I’m concerned about is that you (or others) will read my answers and feel like it’s judo — I’m avoiding disagreement by saying “oh, I can do that too, architecture can be agile”. Judo is seen in another architecture book I recently read, which is actually a thorough description of how to apply up-front design, when it describes how to reformat itself to be Agile, Scrum, etc. But that reformatting was unconvincing, because it said things to the effect of “Use iteration 0 for six months to develop a product line architecture”, which would be contorting things too much.
I would be delighted if Agile developers read my book and never bought a CASE tool, and didn’t change the code they write, just so long as they agreed that they need words to describe big chunks of code and communication channels, need to distinguish the module, runtime, and allocation perspectives, and need to deliberately choose styles that promote the quality attributes they want.
And I’d be happy to be wrong about my ideas, so long as I can understand that and fix them. I hope I’ve been clear to you that if you have misinterpreted my work so far that it’s my fault for not being clearer, or for hinting the wrong direction. And boy am I thankful for your time and ideas in this discussion!
Regards,
-George
This is a letter to my friend Larry Maccherone, who is an expert on software processes and Agile in particular.
Larry,
Here’s something I’d like your opinion on, and it might become another blog post for you. I believe we should try to understand engineering activities separately from management activities. It’s tough to disentangle them, but regardless of management process you’ll need to decide what the system should do, assign responsibilities to parts, and think about (analyze) if indeed the thing you designed/coded will do what you were asked functionally, and if it will have acceptable qualities (performance, modifiability, etc.)
I also believe that success depends on aligning the management and engineering activities. XP and other agile practices are actually a nice merging of the two. Engineers on space systems may be forced into waterfall processes (you can only launch a rocket once) and XP developers may use iterative processes (you can relaunch the website each week), but both have the same engineering vocabulary — processes, modules, analyses, tests, etc. My goal with the architecture book is to help popularize the software architecture ideas (mostly the CMU/SEI versions of those ideas) and help them become de facto standards across all engineers/developers. For example, Szyperski’s definition of a component is pretty different from the CMU/SEI definition, and his book is not so old. My book is actively trying to avoid promoting a particular management process but instead showing that the core engineering ideas and activities are compatible with a variety of management processes (agile in particular), but that doesn’t make the book title “Agile Software Architecture”.
I hate to think of a situation where two trained engineers are at a whiteboard trying to solve a problem and they do not have the right abstractions / models to think about and solve their problems. Sure, they’re bright, so they figure something out ad hoc from first principles and some fuzzy intuition about chunking large bits of software. But I’d like them to have a standardized, shared vocabulary of parts (components, connectors, protocols, properties, etc.) that are effective for understanding the problems they face. (That’s the “abstractions” part I discuss in the book’s introduction). And over time we’d be more effective at sharing our solutions (which is the “knowledge” part from the intro) the way design patterns were a success. Right now, most folks have a hard time seeing that the styles used in operating systems are effective there, and the styles used in IT systems are effective there, but a client-server OS or a CSP billing system is probably a bad match. Another example of this is folks arguing that “your language is stupid”, because it’s not a good match for problems from a different domain (e.g., Java is probably not the best choice for OS device drivers and ditto for C and billing systems).
I’d be happy to hear your thoughts on any of this, but in particular on these questions:
Regards,
-George
Following architecture-centric design means that you are using the architecture to ensure a property or to achieve a quality attribute. Code can diverge from the design, often unintentionally, and disrupt your plans. We can use architecture hoisting to ensure that the code has those same properties or qualities as the design.
Architecture hoisting is the direct ownership, management, or guarantee by the architecture of a feature, property, or quality attribute. It lets developers depend on the architecture for the hoisted feature, property, or quality. This usually entails writing the application code separate from the architecture code, so the architecture has a tangible existence in the source code.
Architecture hoisting is an outgrowth of architecture-centric design, but hoisting entails localized code that you can point to and say, for example, “This code handles transaction independence.” Conversely, architecture-centric design may be seen only indirectly in the source code, or the quality may be emergent from the design. The components as designed may result in a high peformance system, but there is no one part you can point to that localizes the management of performance.
Hoisting of features is commonplace. Imagine that your system must log all access to a resource. You could say, “Everyone using the resource should log their access,” but if someone forgets then the invariant is broken. Alternately, you could encapsulate the resource behind an API that logs all accesses. Doing so ensures that the logging invariant is satisfied.
Hoisting properties or quality attributes is less common but there are some mainstream examples. An application server is software that handles runtime qualities of an application and they are often used for web applications. A developer writes an application and the application server handles running many copies of it on a single machine (hoisting concurrency) or even spreading out the copies across multiple machines (hoisting scaling). An Enterprise Java Bean (EJB) application server hoists concurrency, scalability, persistence, and transactions. In fact, an EJB application server can be seen as an improved Servlet application server that is more effective at hoisting concurrency problems.
The Eclipse framework hoists many features, properties, and qualities, such as resource management, concurrency, and platform independence. The Eclipse framework can be extended with plugins, which can be recursively extended by other plugins. Plugins must know how to load the plugins beneath them, but doing so incorrectly will break the framework’s properties. Erich Gamma and Kent Beck’s book describes how to load new plugins and still maintain the “Diversity Rule” property (Contributing to Eclipse, pp 72-73, 2003). Although Eclipse has since switched to using OSGi, this code reveals identifies an opportunity for additional hoisting: if the framework itself was responsible for loading plugins, it could ensure that the Diversity Rule was maintained.
When properties or quality attributes are hoisted the application may have to follow some constraints in order to work within the architecture. For example, EJB disallows applications from starting their own threads, creating a GUI, or writing to local disk. These restrictions make sense, since it would be difficult for EJB to handle concurrency when applications created their own threads, or move applications between servers when they have data on a local disk.
Tradeoffs may be seen when hoisting. Automatic garbage collection hoists memory management but can make achieving performance targets difficult. Domain-specific concurrency patterns may be more efficient than a hoisted general-purpose mechanism.
Architecture hoisting can be seen as a kind of tyranny over developers, burdening them with additional constraints and bureaucracy, or it can be seen as liberation for developers, freeing them to focus on functionality instead of properties and quality attributes. Hoisting is just a mechanism and can be used appropriately or not. It can be most effective when the system design requires properties or quality attributes but achieving them would be a burden to developers. Often developers may be experts in the domain but not on how to ensure a quality like security or performance, so hoisting can enable experts to work within their specialty.
EDIT 20 March 2009: Thanks Bradley for pointing out the Eclipse change to OSGi which makes the plugin loading example a bit out of date.
My friend Nels Beckman is writing on how to do functional programming in Java. He asked me why I thought people build systems that follow an OO decomposition. Since my boss has been relentless about getting the book done, I have not posted a blog recently, so here’s my note to Nels.
When you decompose systems, at some point you have a chunk (module, component, …) that you want to structure internally. How do you do that? One of the strategies is to mirror domain concepts. This actually works fine in most IT cases (and probably most others too, once you get used to it). There is an argument that the domain concepts (nouns) change very slowly, while the their behaviors seem to always be evolving (verbs). So if you align your structure with the nouns you get less churn induced by the domain changing. This OO strategy implicitly promotes modifiability.
Your suggestion to use a functional programming style is similar to the “orthogonal abstraction” I describe in the book — in the functional case it is usually some math formalism, hence the desire to work with tuples instead of a domain-specific concept. I can see two big advantages to the orthogonal abstraction. First, it could be much faster (or some other quality attribute). In fact it would be surprising if the OO strategy was the fastest — why would the way things are “in real life” naturally align with performance? And second, it could be that there is a domain that has already been well studied (e.g. compilers, databases, static analysis) that has its own set of (stable) abstractions. Experts have decided that these are the essential concepts and they work well.
A day in the life of an IT programmer is a frustrating exercise in what is not known. It is not about engineering a great solution to a known problem. Perhaps this is an under-appreciated fact in academics, and it would explain many prejudices. You’re just some guy trying to make the system do what the marketing / sales / customers want it to do. You never understand the domain (banking, inventory, insurance, etc.) as well as the experts. You are always building an approximation of what they’d really like to have. They always wish it was already built and you always build it too slowly. What you built yesterday doesn’t really support what they want tomorrow. I think systems/OS guys feel less like this — they have less churn in their domain and they spend more time working on optimizing the internal implementation of a module/component.
There’s a story about building a system to track boats on a lake. The first design is an OO one, with classes representing boats, trips, and fares; it can tell you what the cash register should hold at the end of the day. The second design is minimal: just keep two counters that sum the departure and return times of each boat. At the end of the day, subtract the departure counter from the return counter to get total minutes and multiply by rate. Ta da. But if you ask for any change to the OO system (say discount fares after 5pm) it’s easy to add because the change is relative to the domain, which is already encoded in the design, while the other solution has pruned the problem to its core, so you’d have to start over to change anything. I’m not saying this story is accurate — it’s a fable so it’s exaggerated — but the nugget of truth is there, including the extreme simplicity of non-OO solutions. (If anyone knows the origin if this fable please let me know).
Components and connectors are the backbone of the runtime view in software architecture, but the connector appears to play second fiddle to the component. The 1968 NATO conference that coined the term “software architecture” specifically asked for components, but did not mention connectors. Components are shown as two-dimensional boxes, while connectors must make do as one-dimensional lines.
Despite the perception of connectors as simple data movers, real work can be done in connectors. Connectors can convert, transform, or translate datatypes between components. They can adapt protocols and mediate between a collection of components. They can broadcast events, possibly cleaning up duplicate events or prioritizing important ones. Significantly, they can do the work that enables quality attributes, such as encryption, compression, synchronization / replication, and threadsafe communication. It is hard to imagine systems achieving qualities like reliability, durability, latency, and auditability if their connectors are not contributing.
You may recall writing your first essays in high school and struggling with introductions. There was probably some advice about going from the general and honing in on your specific topic, and ending up with a topic sentence. Over time this got less painful (both for you the writer and whoever had to suffer through your essays), but the introduction to a book is a whole new world of hurt. You’re trying to hook in and interest folks who come with any number of prejudices about your topic, experts and novices, academics and practitioners. Of course here when I say “you” I really mean “me” because that’s what I’m struggling with for my book intro.
What I’ve posted below is the N-th rewrite of the first few paragraphs of the intro. I’m not happy that it starts out with Agile programming, and may paint them too much as the enemy of design, but here it is for your enjoyment. Comments are, as always, gratefully appreciated.
Over the years, software development practices have become so burdened with heavy techniques that a rebel group, known as Agile developers, has sought to pare the development process down to a minimal core. Agile developers emphasize the developer’s skills in crafting the parts of the program they directly manipulate, usually objects and classes, and de-emphasize analysis and design. Although they are careful to point out that Agile techniques only work on a subset of projects, it is clear that there is rising mainstream disdain for analysis and design, which includes software architecture.
When a grizzled coach and a rookie watch the same game, the coach sees more than the rookie not because his eyes are more acute, but because he has built up a set of abstractions in his head that allow him to convert what he perceives as raw phenomena, such as a ball being passed, into a higher level understanding of what is happening, such as the success of an offensive strategy. Software architecture research started after developers had been successfully delivering systems for decades, but its goal is to understand and encode the abstractions that veteran developers can see but the rookies cannot. When that knowledge is successfully transferred, it accelerates the progress of the rookies into veterans.
What a developer sees and understands is different than the software development process he follows. A smaller project team may all work in the same room and occasionally sketch on whiteboards, while a larger project may be distributed and need to publish documents that describe their designs. But both teams need to understand the core software architecture abstractions and be able to make design decisions that reconcile opposing design forces. Both teams will understand that any kind of engineering, including software engineering, requires understanding the risks of failure and how to apply appropriate techniques to mitigate those risks.
Smaller projects may be adequately served by existing abstractions, such as objects and methods, but mid-sized and larger projects will benefit from the use of higher concepts such as components, connectors, and ports. This book describes how to efficiently use software architecture concepts and techniques to address risks faced by your project.
If you decided to create some abstractions to explain the architecture of existing software, it is unlikely that you would end up with the standard set of architecture abstractions (components, connectors, ports, roles, etc.) The standard set of architecture abstractions seeks to point future software development in the right direction, and so it is prescriptive in that it encourages encapsulation and clear channels of communication.
When we document existing systems, we are simply describing them as they are. Consequently, there are some challenges when we try to simply describe software that does not conform to our ideals. Much of what we find is beautifully designed, but not everything. We will have trouble with systems that have no internal subdivisions and are a bowl of object soup. We will have trouble with “glue code” that expediently interconnects other systems and is often written in terse scripting languages. Above all, we will have trouble with frameworks because while our abstractions encourage encapsulation with components and narrow interfaces defined in ports, frameworks often reveal their implementations through inheritance hierarchies and have wide and poorly defined interfaces.
Note to Kevin and Ciera, if you are reading this: we still need to write that paper on the framework definition language, which would be the first step towards reconciling architecture abstractions and frameworks.
A while back I posted a list of things that are hard about software architecture, and this posting is an elaboration on that list that will make its way into the software architecture book.
Comments on this list are welcome. In fact, if you have a pet peeve about software architecture then it can probably be refactored into an entry in this list.
The Unified Modeling Language has a diagram type for showing classes: a class diagram. A class will have instances, but UML does not have a straightforward diagram type for them. People often use the UML collaboration diagram to show a collection on instances, which is also called a “snapshot” because it shows just an instant in time of a running program.
Separately, software architects have identified three primary viewtypes: Module, Component & Connector, and Allocation. (See Documenting Software Architectures). Each viewtype is a category containing many views, such as the class diagram and snapshots we just discussed. Viewtypes are by definition hard to reconcile with each other, but it is easy to reconcile views within a viewtype. Let’s rename the “Component & Connector” viewtype to be the “Runtime” viewtype because we’re generalizing this viewtype to include all runtime views.
I have worked with information models and snapshots, and separately thought about module and runtime viewtypes, but today I recognized a connection between them. Information models, such as UML class diagrams, are a kind of module viewtype. You can inspect the source code (also part of the module viewtype) and directly see the classes and their attributes.
Instances, however, are not created until runtime, so are part of the runtime viewtype. You cannot see instances when you look at the source code unless you “run the code in your head” to envision what it will do.
There’s an interesting wrinkle though. A UML class diagram often includes more information than you can directly inspect from the source code. For example, the program might respect the invariant that a Vehicle has an even number of Wheels. You can’t tell this by looking at the code superficially, you’d have to either run the code or exhaustively analyze the code to validate the invariant. A class diagram would show the Vehicle and Wheel classes with an association, and the multiplicity would be EVEN, or have an equivalent annotation. So a class diagram is only mostly in the module viewtype.
My friend George Figgs is a linguist and has the following to say about the mad libs metaphor for frameworks:
the madlib metaphor/concept also conjures up Chomsky’s arguments, where you can have a grammatically, i.e. syntactically, correct sentence that doesn’t make any sense semantically, as in the famous “colorless green ideas sleep furiously”, and from Lewis Carroll’s jabberrwocky – “twas brillig and the slithy toves did gyre and gimble in the wabe”.
these sentences are grammatical, as all of the necessary syntactic slots are filled with grammatically appropriate lexical items, but are ‘buggy’ in these sense that they’re filled with semantically infelicitous lexical items.
i don’t know much about frameworks, but this seems similar to unification based grammars, such as construction grammar, where, in order for sentences to ‘work’, they have to unify both lexically (‘type of food’), and semantically (“commonly eaten by humans”), to avoid the utterance being semantic gibberish.
This is interesting because there may be a way to use the formalisms already created in linguistics to explain or specify frameworks. It’s also good because it reminds me of a problem with frameworks in that they have deeper semantics than the OO language syntax expresses. For example, a framework superclass callback method “aMethod(int x)” could mean any of the following to the framework plugin:
All of these possible interpretations inspired Kevin Bierhoff, Ciera Jaspan, and I to sketch out a paper on what a framework language would look like. If only we’d follow through on that. :-)
I realized yesterday that a great way to explain how frameworks work, and how they are different from code libraries, is to compare them to a Mad Lib. This metaphor isn’t for computer science types, but for “lay people” like my mom. Until now, I hadn’t come up with an example of something in the real world that acts like a framework, where the skeleton is separate and you fill in parts.
For those who don’t know what a Mad Lib is, you can see them in action on this site. Basically, it’s a sentence that’s missing some parts. You supply the parts, like “a person’s name”, “an adverb”, “a food”, or “a place to eat dinner”. In a Mad Lib, these parts are placed into a sentence you haven’t seen yet, and hilarity ensues: George was sexy hungry, so he ate his turnip salad on Mt. Everest. The incomplete sentence is the framework, and the additional words are the new part of the program you would write to extend the framework. Of course Mad Libs are funny because you don’t know the sentence in advance, but extending a framework is hard in the same way because your knowledge of the framework is imperfect and that leads to bugs.
This metaphor makes one characteristic of frameworks clear: The framework owns the skeleton of the application. By adding your words, you can complete the sentence, but you can’t take the sentence somewhere else. In the above example, you can’t turn it into a discussion on human rights. Ok, maybe you can shoehorn or “hack” it into political commentary: The prisoner at Guantanamo being held in violation of Habeas Corpus was not fed for a week so he was very hungry, so he ate his mattress from his 6×6 foot cell salad on advice from the Red Cross. But clearly it’s not the kind of sentence you’d write if you had control over the skeleton, which here is owned by the framework.
When frameworks were first described, they were presented as incomplete solutions to problems, much like this Mad Lib sentence. That is, the sentence makes no sense until you add the missing parts. People talked about “instantiating” the framework. Modern frameworks often stand alone, but also allow you to add parts. Continuing the metaphor, it’s like the parts are independent clauses (or some other sentence part that I should have learned in high school). The sentence might be: The web server served pages. That makes sense by itself, but we can extend it this way: The concurrent, caching, SSL web server served banking pages. It’s a sentence that still provides a skeleton and extension options, but it’s standalone.
So if frameworks are Mad Libs, what is my research on Design Fragments? While Mad Libs are a game to make funny sentences, engineers use frameworks to build useful things. Engineers don’t mind repeating themselves and being boring so long as it gets the job done (this is true perhaps beyond the domain of Mad Libs). Design Fragments describe known-good ways to fill in the Mad Lib so that it “works”, i.e., it’s grammatical. My empirical study found that once engineers discover a way to fill in the framework, they copy that solution over and over. Design Fragments are a kind of recipe describing how to fill in the framework successfully that can be checked by the computer to ensure the recipe has been followed.
For those of you familiar with design patterns, you’ll see Mad Libs as very similar to the template pattern, where an abstract algorithm is described in a superclass and whose particulars are completed in a subclass. (Please ignore the subclassing mechanics of the template pattern — the important part is the intent). With the template pattern, you have to fit into an incompletely specified algorithm dictated by the superclass, and so you have an obligation to somehow complete your part, and observe some (usually unwritten) contract or constraints. Note that in the Mad Lib, if you give it a noun when it asks for an adverb, the resulting sentence just won’t make sense.
You can implement a framework many ways, including using the observer pattern, or using function pointers. Note the difference in intent between the template method and observer/function pointers. With the template pattern, you have to fit into an incompletely specified algorithm dictated by the superclass, and so you have an obligation to somehow complete your part, and observe some (usually unwritten) contract or constraints. With the observer pattern (or raw function pointers), the model notifies observers that a state change has happened but should not expect them to do anything, i.e. there’s no contract. Put another way, the model in the observer pattern should never break if an observer fails to do something, while the abstract algorithm part will usually break if the plugged in part doesn’t do what it is supposed to.
I believe that most framework hot spots really have contracts associated with them, more like the template pattern. My bias is that I think frameworks often pretend that the hotspots have no contracts, but usually they have hidden contracts.
Once you articulate a vision of how software architecture could be done well, which includes the creation of models that enable analysis, the next question is, “What analyses can I do?” At this point we can either go down the path of somewhat obscure academic efforts such as rate monotonic analysis or queuing theory and pretend that they are appropriate for mainstream use. Alternately, we could admit that there really aren’t many architecture analyses yet. Let me suggest a third path.
Human brains are remarkable at processing information, but quite dependent on the form of that information. Imagine trying to navigate from NY to LA if you were given an alphabetical listing of the street segments in the country. This would thwart a human but impede a computer only slightly. That’s because people have lots of visual processing capabilities that we use to find a route on a map. Maps are drawn to work with those capabilities, for example by drawing major roads thicker than minor roads.
Analysis of software architecture can do something similar. If a human is searching for single points of failure in an architecture, he’s going to have a hard time if he only looks at the source code. However, the fact that all requests flow through a single load balancer would jump out when looking at an allocation view.
The follow-on question is: Do standard architecture views (like allocation, runtime, and module) provide the right representations for humans to leverage their built-in analysis? I do not (yet) have a way to give a refutable answer to this question, but my experience is that Yes, the standard architecture views are good, but No, they are not ideal. The standard architecture views are general-purpose, which gives them leverage on almost all domains. The flip side to this is that they provide no domain-specific leverage. For example, a calendar has the nice property that all the Mondays are in the same column – a domain-specific encoding that you wouldn’t get from the standard architecture views.
David Garlan recently asked me what I thought about data modeling and its relationship to software architecture. I’m including the answer here because it was effective at articulating some of my philosophical assumptions about software architecture that are not shared by all researchers and practitioners.
Since data(base) modeling commits to a data representation, it hurts your ability to zoom out. It also introduces discussions of N-th normal forms and efficient use of varchar vs. string(20). What MAp calls “information modeling” commits you to the existence and relationship between types, but not their concrete data representations, which allows it to uncover design defects related to the problem domain.
Data modeling is a large and specific concern at companies, because the data and its schema may span applications and outlive all of them. It may have a place in architecture descriptions simply because its significance to companies, but I am unconvinced that it is an architectural style or at the same level of abstraction as the rest of the software architecture ideas.
This was a question from the CMU software architecture class that I think highlights a common misunderstanding.
Is there any real difference between a component and a connector? I tend to take connectors as:
For example, in a typical drawing of the architecture of web services, you wouldn’t see the web server.
(You would see a web container, but that is something different).
The web server is reduced to a connector between the client and the web-tier components, because we do not care too much at this level from this angle.
It does not mean a web server is not important, or it is very simple; it’s just we “choose” to hide it in this particular diagram. It does not have to be hidden always. When we want to discuss the link layer security or load balance of the system, the “connector” shows up as a group of components.
It is the same for the pipe-n-filter C&C view we had in the class. Making a “pipe” a connector is only adequate if you “choose” to focus on the filters on this diagram. If the pipes are intelligent and can consume all your available memory, as I have seen in some proposals, we may choose to express them as separate components in some other diagrams.
If we accept this vague definition, can we say a connector is roughly the same as the “association” in UML? We can always beef up an association with class or stereotype to give it more meaning.
One way to think of this is that you don’t need any of these abstractions: components, connectors, ports, roles, … But many people find them useful, especially as you think about larger systems.
Components “do work” while connectors “move stuff around”. When you look closer, “moving stuff around” is work in itself. So in that sense connectors and components are equivalent. But you could also say that neither one exists at all, and it’s all just machine instructions. You aren’t wrong to think of everything as machine instructions, but you will not get much leverage on harder problems.
Regarding your last point, associations in UML are different than connectors. First, associations are between objects, not components. I would use a UML association to represent the “head” pointer in a linked list data structure. Second, associations imply only that there is a relationship between the objects, not that they communicate. I don’t think of the head pointer communicating with a node in the linked list. Connectors are helpful when you want to tell the reader that two components communicate over a channel (and the usual “closed” semantics means that they do not communicate in other ways).
This past weekend I was chatting with Ciera Jaspan about her work on frameworks. We chatted about Bill Scherlis’s observation that framework interfaces are wide, while traditional library interfaces are narrow. As I mentioned briefly in a prior blog posting There is another difference you see in frameworks — some interfaces are deep, others are shallow.
In saying that frameworks have wider interfaces than libraries, Bill is saying that a client program using a framework interacts with many framework objects, unlike a library where you would typically interact with just one object. The second dimension, deep vs. shallow, addresses how deeply the client traverses into the data structures. In Eclipse, for example, you often find code like this fictitious example: parent.getWorkbench().getMenuManager().getToolbar().add(myNewItem). Let’s call that deep, since it allows the client to dig deeply into the data structures exposed by the framework. Shallow interfaces would expose a limited set of objects to the client, perhaps just one level.
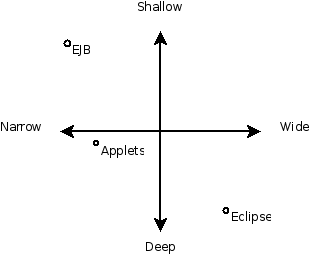
These dimensions become interesting when you ask “How can I design my framework to be comprehensible by mortals?” The closer your framework is to the top left (narrow + shallow), the easier it will be for developers to understand and use correctly. You can think of two competing forces: One pulling to the bottom right (wide + deep) because it’s easier for framework writers to build and requires less up-front planning, and one pulling to the top left (narrow + shallow) which is easier to use.
There is lots of hype today about Service Oriented Architectures, and there has been longstanding interest in making software services available remotely using remote procedure calls, CORBA, RMI, etc., but this is hard to do with deep + wide framework interfaces. Of the two, deepness is harder to enable remotely. Consider the fictitious example above, and realize that it would translate into four remote calls. A shallow interface would require fewer remote calls, or even just one.
The wrong way to interpret these insights would be to assume that all frameworks should be narrow and shallow, and that it’s just ignorance and laziness of framework writers that has given us wide and deep frameworks. Instead, we should try to develop heuristics to guide the choice for framework writers, because some domains will be amenable to the narrow + shallow frameworks (like EJB), while other domains may require either interfaces that are deep, wide, or both.
Here’s my mini-taxonomy of object-oriented frameworks that I have not seen elsewhere. I define frameworks as code that uses the inversion of control pattern, where it “calls you back” (the so-called Hollywood Principle).
1. Domain frameworks. These were the original frameworks, from Smalltalk. They gave you a bunch of objects that worked together, effectively showing you how a domain works. You have specific places where you can extend the framework.
2. Quality attribute frameworks. These are newer. They grab a quality attribute and hoist it such that framework users don’t have to worry about that quality attribute. They are generally domain-neutral. Example: While Struts is just a domain framework (handles web requests), EJB is a quality attribute framework that hoists concurrency, distribution, and coupling pretty well, and security quite poorly.
Bill Scherlis likes to point out that framework interfaces are wide and deep, while traditional API’s are narrow and shallow. I’ve been experimenting with refactoring a framework interface so that it is narrow and deep (and yes, I need to blog about that too…), which makes me wonder if other combinations in the {wide,narrow} x {deep,shallow} space are interesting. Perhaps it is interesting to have a wide interface where you only get back simple objects, with no chaining like you get in deep interfaces, for example in Eclipse: “grab the Workspace, then the window, then the menu manager, then the menu, then ask the menu to add an item”.
Book: Domain Driven Design, Tackling Complexity at the Heart of Software
By: Eric Evans
Publisher: Addison-Wesley, ISBN 0321125215
This is the only book I’ve seen that explains what good object-oriented developers do when they incrementally discover a domain by interviewing subject matter experts and building models. The book uses fictitious dialogues between a developer and a SME, which accurately capture the SME’s initial lack of confidence in the process and the transition into trust and effective collaboration. The book also documents a number of useful patterns.
However, it would have been a better book, a book with a wider audience, if it had refrained from preaching about agile software development. Or even if the book were organized around a series of essays, and just one of the essays was about agile. But instead I found myself arguing with the author when the commentary about integrating modeling with code came up. This commentary didn’t have the requisite “agile hedge” regarding “don’t try this at scale”.
I support integrating modeling and code when possible. But recently I’ve been on too many projects with large scope (big NYC banks) and non-technical subject matter experts. The book advocates models that are just slightly more abstract than the code, but these would have been rejected by the SMEs. There is a benefit to having models at various levels of detail, though it introduces challenges with keeping them updated and relevant. I would personally enjoy being on smaller projects using XP or another agile method, but someone has to slay the ugly dragons on large, brownfield projects.
Pages 47-49 contain a critique of analysis models, that is, those models that aren’t directly represented in the code. The identified problems with analysis models are: 1) Cannot be used for implementation since implementation concerns not considered during construction, 2) Knowledge gained during model creation is only partly captured in model, so is lost during transition to implementation, 3) Crucial discoveries about domain occur when designing the implementation, 4) With separate analysis and design models, a) modeling is less disciplined so less useful, b) designers may not get access to domain experts, 6) (bold) Deadly divide occurs between analysis and design where insights in each do not feed back to the other.
I’ve seen most of these problems in practice, so it’s good that they are enumerated. Either you can avoid analysis models, or you can be forewarned and forearmed.
I got a great email from my friend Alan B. today about my SOA definition blog posting. He too has been concerned about its definition and offers the following to work towards a definition.
I’d like to find a definition of Service Oriented Architecture (SOA) as an architectural style. The definitions I’ve seen so far are not clear enough in that they do not exclude enough.
The Wikipedia’s entry is clear enough about lack of consensus:
There is no widely agreed upon definition of service-oriented architecture other than its literal translation that it is an architecture that relies on service-orientation as its fundamental design principle.
One problem with using this to define an architectural style is that it would include client-server, n-tier systems, and other styles that SOA presumably wants to be distinct from.
When Paulo Marques visited our research group, he provided a reasonable definition. His definition was that the SOA style prohibited certain kinds of connections to components, such as directly accessing its database, or dropping a chunk of data, or screen scraping. I like the trajectory that thinking takes, because it both excludes certain kinds of systems and, like any good style definition, does not refer to implementation decisions (like SOAP messages).
I’ll continue to look for a definition that is helpful to me.
As you doubtless know, gentle reader, I did my thesis research on software frameworks. Specifically, I found that client code interacted with frameworks quite consistenly, and I developed a technique, called design fragments, to specify patterns of client-framework interaction. Client code is still scattered around many classes, but the design fragments make the connections between these classes apparent.
An open hypothesis was that it was possible to refactor the frameworks to avoid the scattering of code in client classes. If such refactoring were possible, client code dealing with a particular feature, say adding a menu item, would be located in a single place. Client code would be easier to read and might not need design fragments. So if a client wanted to create a user interface with a tree view and a menu, the code might look something like this:
public class SampleView extends GView {
public SampleView() {
this
.useFeature( new TreeViewFeature() )
.useFeature( new LocalToolbarMenuFeature() )
}
}
Now that I’m done with my PhD, I have some time to a) breathe and b) work on side projects. This posting is an interim report on the framework API refactoring I’ve accomplished.
The feature interaction problem is well known inside of telephone systems. In that domain, you may have call waiting and 3-way-calling features on your telephone, and they interact with each other because they both use the same scarce resources: the telephone input and output. For example, if you are talking to a friend and press the hook once, it will alllow you to start a 3-way-call. However, if someone calls during another call, that same hook press will transfer you over to another call. I had experience with this problem when I worked at Nortel, helping to design a clean-sheet implementation of their call processing software.
Here’s my initial list of things that are hard about software architecture. Many are open research questions.
Rhino Research is devoted to improving the state of software practice. We do this by using our industrial and academic roots to give you the freshest and most practical advice in classes and during consulting engagements.
We have taught classes for many kinds of clients, ranging from regular information technology shops, to huge internet shops, to NASA.
subscribe via RSS






{kind=link}
{kind=link}